
Data in oil and gas has always been large, but is it also big?
Big data is more than Petabytes of seismic data or well logs. Big data is a buzzword in modern technology that isn’t clearly defined, yet used to sell expensive hard and software.
What is big data all about?
Big data is associated with huge data sets that often have a higher dimensionality than humans can comprehend without breaking it down to two or three dimensions. Oftentimes big data is associated with advanced processing techniques such as machine learning, data mining, artificial intelligence and pattern recognition.
People following the recent developments of big data hype are criticising that the term “big data” is used very loosely nowadays. So while le can say, yes seismic data is huge. Machine learning to process seismic data has been used in some publications.
The paper „Multidimensional attribute analysis and pattern recognition for seismic interpretation“ from 1985 states:
The interpretation of exploration seismic data to infer the probable locations of commercial quantities of hydrocarbons has deep roots in pattern analysis. In this paper we suggest a broad-based program or framework for treating the interpretation of seismic data as a problem or a collection of many problems in pattern recognition.
The basis for this approach is the identification of a large number of objective or quantitative attributes which may be combined in a variety of ways via pattern analysis to infer the information necessary to accurately interpret exploration seismic data, and to locate potentially commercial hydrocarbon reservoirs.
But mainly big data in oil and gas is used in reservoir characterization and this is how:
The classification problem
Using any sort of data, in this example it’s core analysis data, we would like to classify data according to properties we deem important. The thesis „Reservoir Characterization and Horizontal Well Placement“ by Wang (2012) looks at core porosity and spatial distribution as the main classes.
First let’s take a look at the synthetic data sets. They’re spatial clusters and the grey shading indicates the non-spatial dimension. In figure (a), clusters one and two are correlated in each dimension while cluster two is randomly distributed and should be classified as noise. In the synthetic data sets, one might wonder why we use a classification algorithm at all, as they’re clearly separated and could be classified by hand, but bare with me as we’ll look at some real data afterwards. In figure (b), we can see a more complex distribution, where again the left and upper cluster are correlated in their respective dimensions whereas the lower “boomerang” consists of random samples and should be classified as noise accordingly.

The thesis uses two different algorithms for classification. Spatial Entropy Clustering (SEClu) and compares it to a standard approach the Generalised Density-Based SCAN (GDBSCAN), the exact working is detailed in the thesis. Loosely speaking, we can say that SEClu uses a fuzzy classification algorithm whereas the GDBSCAN classification is “harder”.
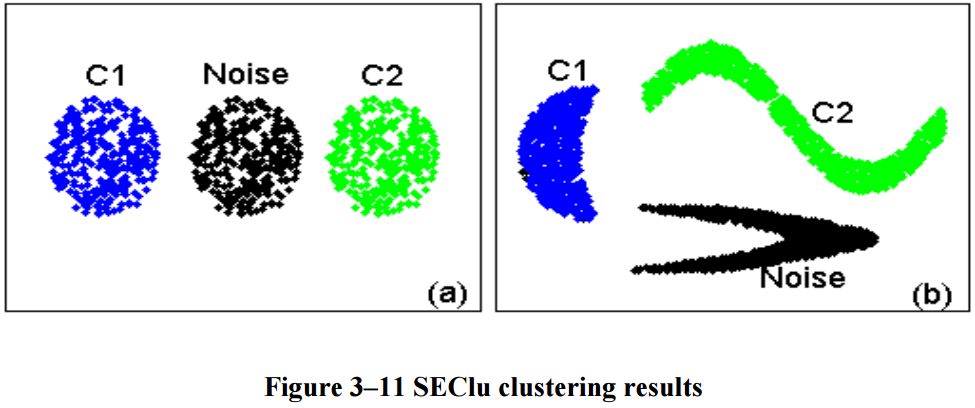

We can see that the test data was classified correctly by the fuzzy SEClu algorithm. The GDBSCAN misclassified the noise as a separate cluster, however. Now, let’s see how fuzzy clustering compares to the standard approach on actual core data from Alberta, Canada.
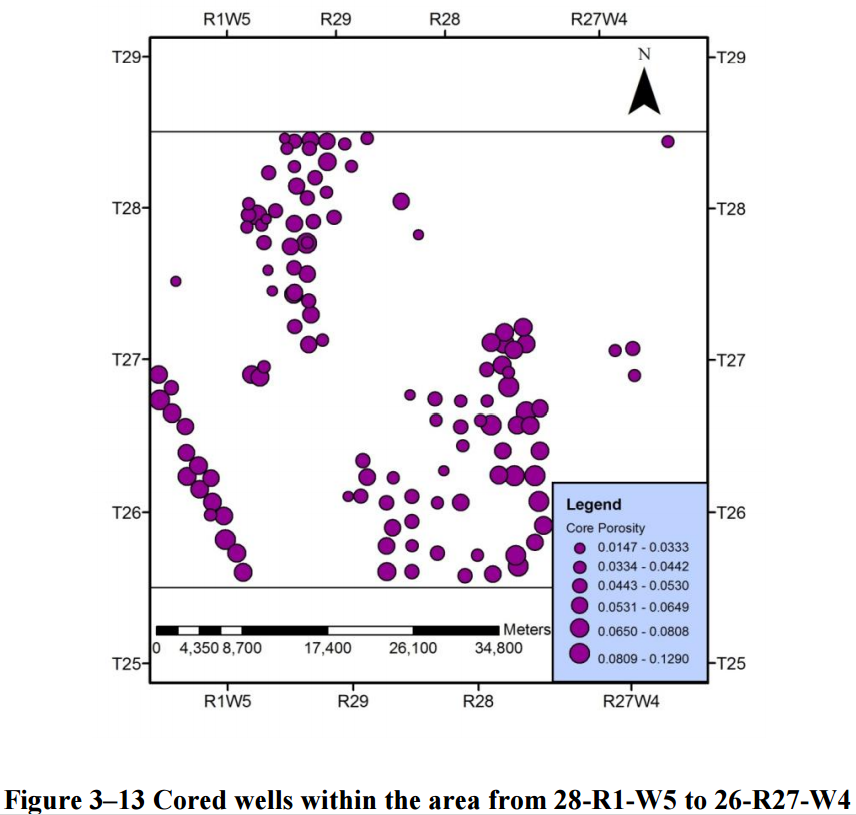
Looking at figure 3-13, we can see three distinct spatial distributions as well as some outliers. Within the main clusters, some more subclusters may be identified, but let’s not get ahead of ourselves. See the data speak for itself.
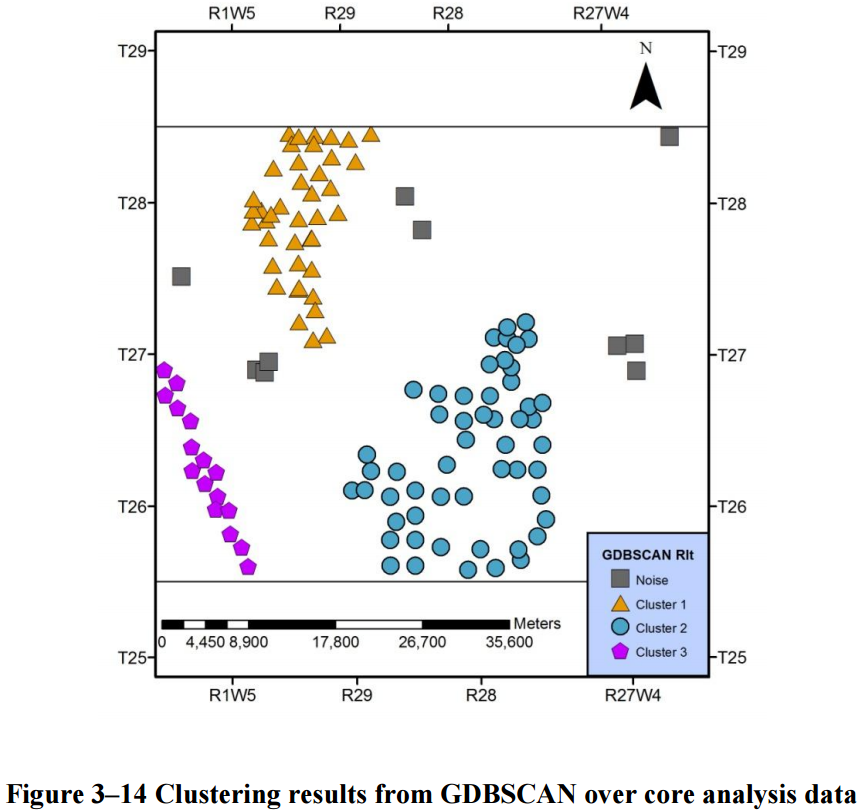
We can see that the GDBSCAN has classified most of the spatially close points into clusters, let’s compare this to the SEClu result.
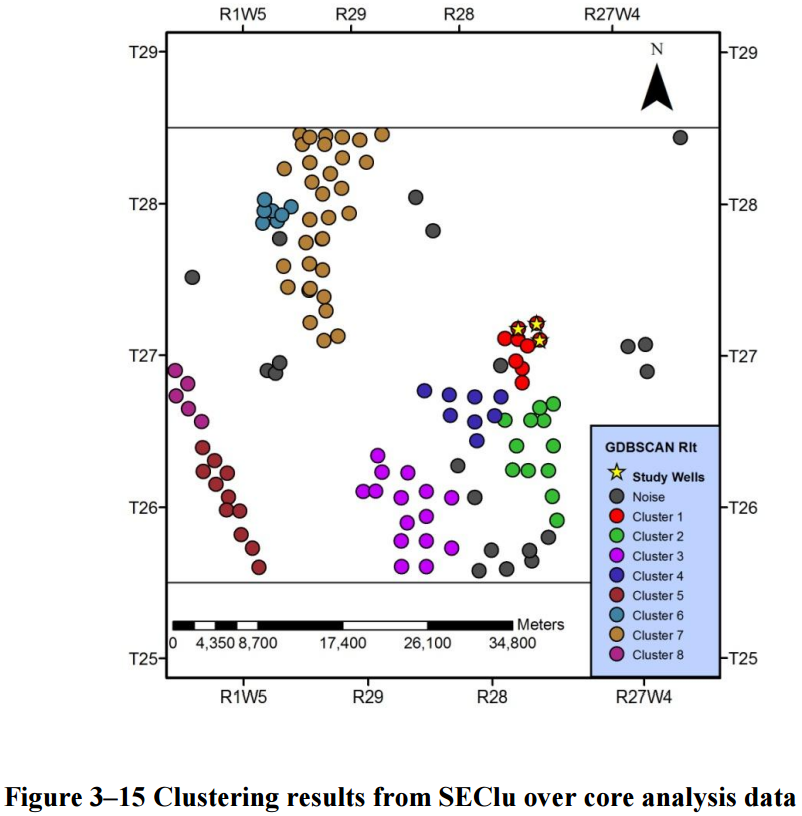
The fuzzy algorithm identified eight clusters in the data set. The spatially correlated clusters are divided into more specific groups according to the non-spatial dimension, core porosity. I rendered animated images of these results to show the classification in direct comparison. Remember that the size of the purple points indicates the size of the pores.
GDBSCAN versus Core Porosity
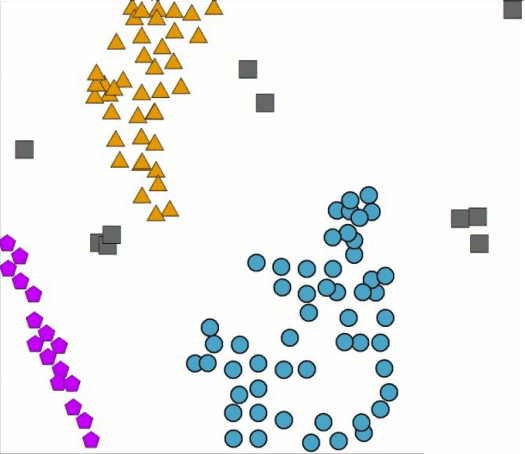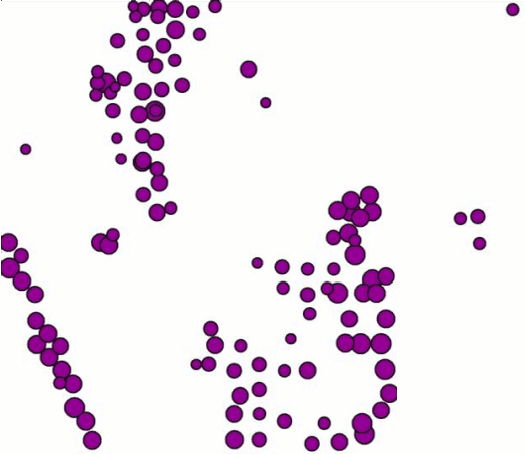
- The gray squares are the noise class.
- Three colored clusters were identified by GDBSCAN.
- The non-spatial dimension has close to no effect on the classification outcome.
SEClu versus Core Porosity
- The gray points are noise
- The noise classification is consistent with GDBSCAN
- Additional noise is identified within the big cluster on the bottom.
- Strong separation of subclusters in spatial cluster on bottom
- Small sub-cluster in the upper spatial cluster.
- Data points close to other clusters are classified into other clusters
- Especially the red – green – blue subclusters
Fuzzy classification
Fuzzy classification of data in oil and gas especially reservoir characterization has proven to be very helpful. We use high-dimensional data and try to make sense of it to get to know a reservoir. Nevertheless, this is just touching the mere borders of big data.
If you would like to read more on big data in oil and gas, leave a comment and let me know!
Jesper Dramsch
Latest posts by Jesper Dramsch (see all)
- Juneteenth 2020 - 2020-06-19
- All About Dashboards – Friday Faves - 2020-05-22
- Keeping Busy – Friday Faves - 2020-04-24